
Opti-Capture
ACCELERATED DATA CAPTURE
Opti-Capture is the solution to classify scanned documents in a distributed environment, utilizing validation adapters into line of business data.
Opti-Capture is designed to bring indexing efficiency and quality control into the scanning process. Scanning is normally executed using high-speed document scanners; one single user normally has no time to scan and classify the document batches at the same time, this is simply because the scanner needs constant attention and the documents must be scanned as quickly as possible to have the scanner utilized efficiently.
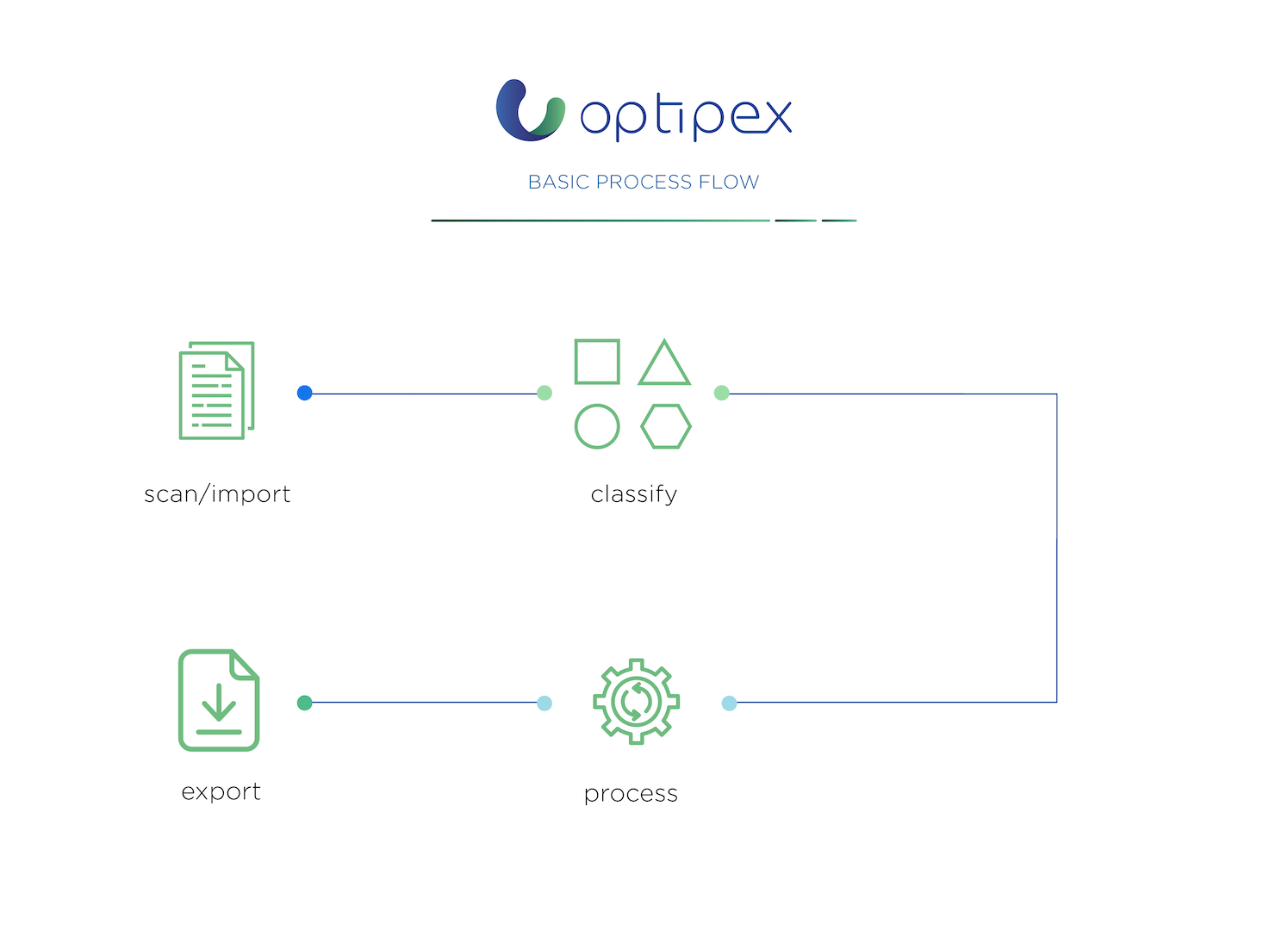
scan / import
- Bulk Scanning
- Import
classify
- Manual Indexing
- Barcode Recognition
- Content-based indexing
- Validation
process
- Desktop Client
- Productivity Report
export
- Export
DESCRIPTION
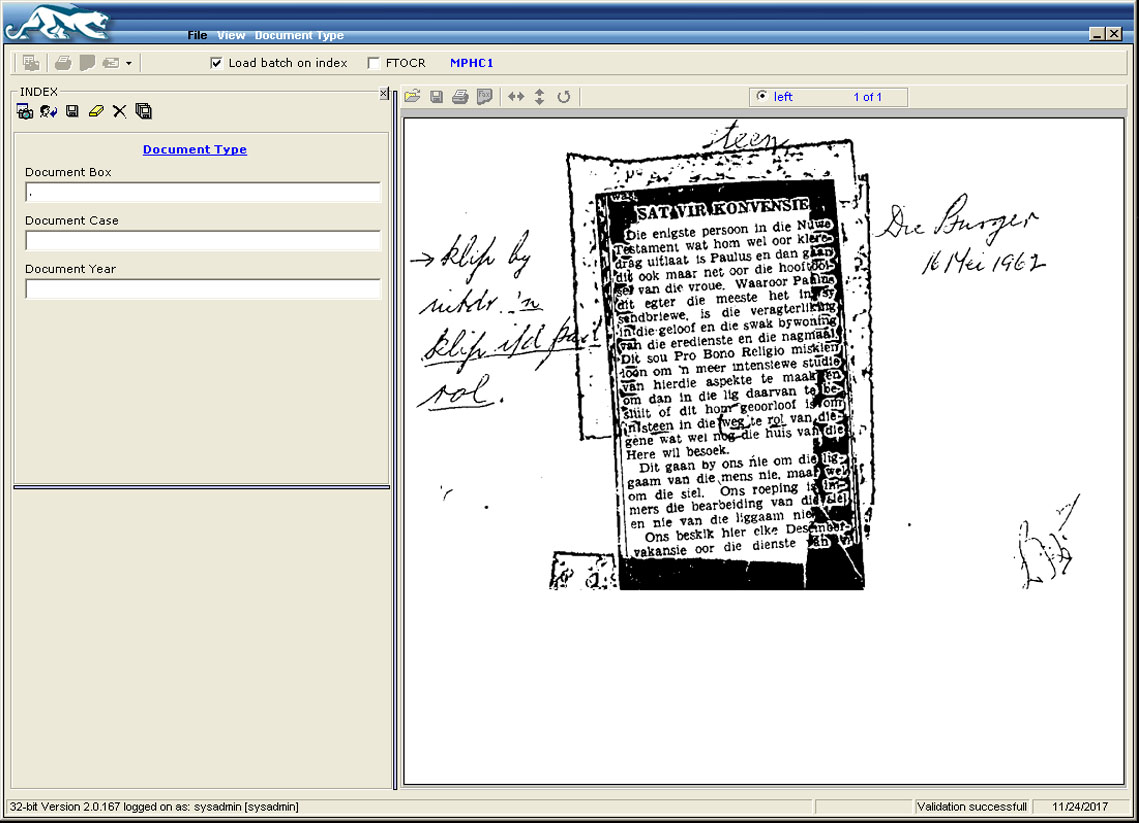
Opti-Capture provides a facility for document indexing post-scanning. Documents are imported into the system manually or automatically by an automated windows service. Documents are displayed in a document viewer for further classification when the user requests the next document for data extraction.
The system can be configured to have a secondary data validation process called Quality Control. This is just to make sure that the initial manual data extraction was completed 100% correctly. Even though automatic data extraction (OCR) sounds more technologically advanced, in some cases manual data capture is just more cost-effective and even more efficient. This is applicable to complex documents where human intelligence is still far superior than artificial intelligence.
The document viewer is capable of basic image manipulation assisting in data extraction, like rotate, zoom-in and out, zoom at selected area, etc.
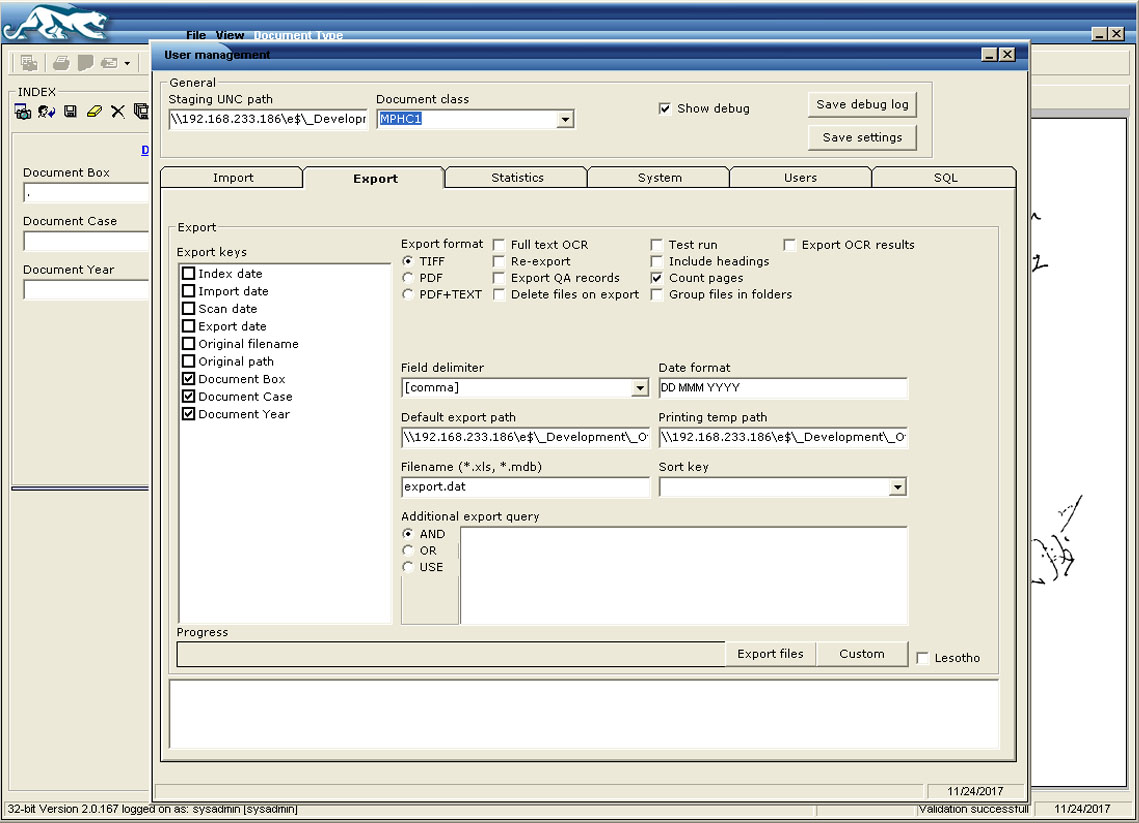
Classified documents are exported into PDF or any other suitable imaging format, with or without full-text OCR.
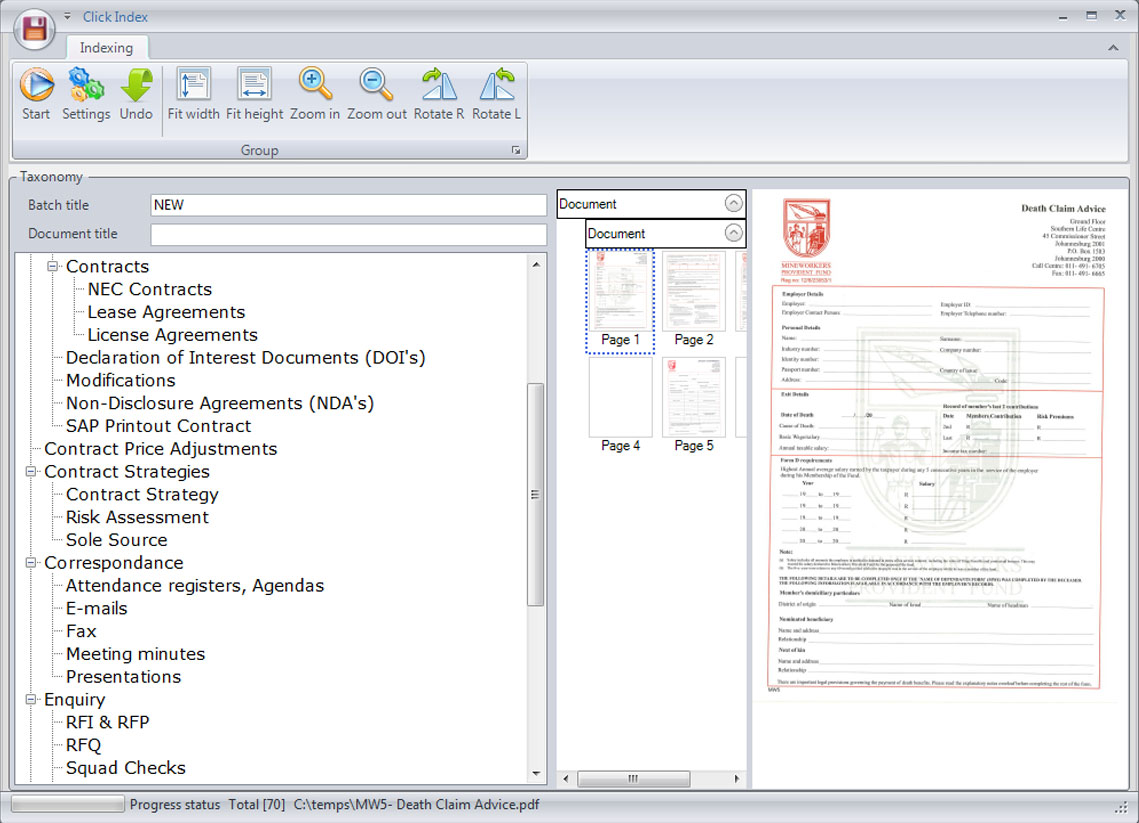
The latest “Click & Index” plug-in allows indexing of documents according to the company’s taxonomy without typing any data, by simply selecting from the classification from the hierarchical classification tree structure.
Featuring
- Automated import
Document can be imported manually or using an automated import service. Once imported, the rules are defined, generally based on first in first out, but more complex rules can be implemented.
- Distributed indexing
Documents are indexed from controlled queues, by a number of indexing clerks.
- Easy document navigation
Document can be easily navigated within the document viewer, by using features such as Zoom in and out, rotate, enlarge on specific areas.
- Simple taxonomy configuration
Taxonomy (document indexing criteria) is configured per document type, and can consist of free text, drop-down lists or data selectors.
- Line of Business validation
The extracted information can be validated against the line of business systems, for example, the ID number is captured and name, surname, and initials are automatically populated from HR system.
- Keystoke blanking
To achieve high-quality data extraction, the keys can be blanked out and verified at the quality control stage. It’s also possible to implement reverse indexing, whereby the number needs to be captured from left to right and theater right to left to ensure data correctness, especially when capturing numbers.
- One or Two level indexing
The documents can be classified and exported or an additional Quality Control step implemented.
- Full text OCR
The documents can be exported with full-text OCR for more efficient searching within Document Management Systems.
- Flexible export
Documents are exported into PDF and could also be exported directly into DMS systems like SBimage, SharePoint, or FileNet.